Adding font fallback to Revery
And other musings about UTF-8/Unicode
Background
This summer I’ve had the amazing opportunity to work on Revery/Onivim full time as a software intern at Outrun Labs, an experience I’ll do a more detailed writeup of near the end of the summer.
One of the goals of the internship was to get font fallback working in Revery and Onivim. Font fallback is one of those features that all GUI frameworks nowadays simply must have. I’m sure we’ve all seen the infamous “unknown glyph” mark at least once. Seeing  or � might be passable for an emoji here or there, but it’s simply unacceptable if you’re expecting to see your native language on the screen.
The problem
Back in the old days, most digital text was represented in ASCII. As far as text encodings go, ASCII is pretty much as simple as it gets – each character is an 8 bit/1 byte integer that corresponds to a character. However, that only leaves us with or characters we can represent. If you’re only ever writing English/Latin scripts, that’s more than enough. The problem with ASCII is its ‘A’ - “American.”
Eventually UTF-8 and Unicode came along with the ability to represent an arbitrary number of characters while still maintaining compatibility with ASCII. Great! Except for one thing – just because Unicode/UTF-8 supports a character doesn’t mean any given font will contain a glyph for it. Here inlies the problem: barring a very small subset, most fonts only have glyphs for one language/script.
As of a couple days ago, if I opened a file in Onivim2 with its default font JetBrains Mono and that file happened to contain any Japanese characters, this is what would show up:
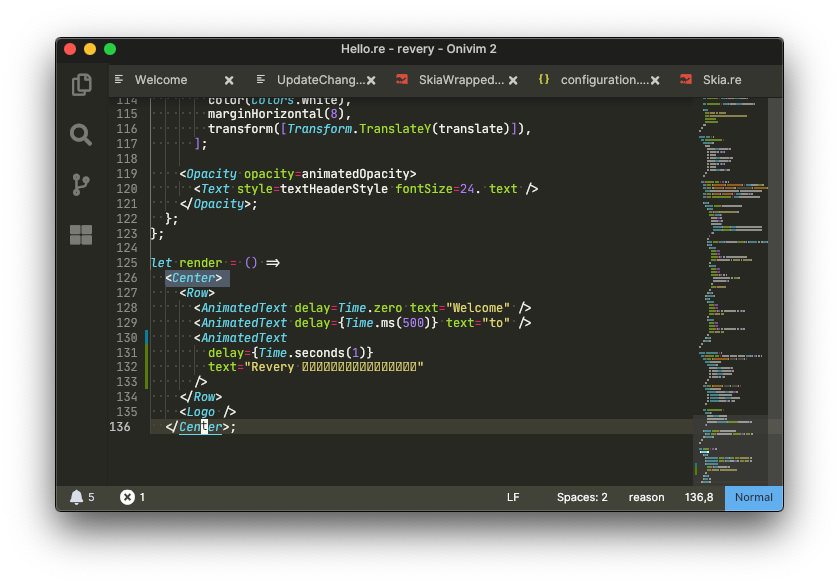
I should note that as of now, Onivim2 is in it’s alpha stage (soon to be beta!), so this kind of bug is to be expected.
The crux of the issue here is that JetBrains Mono, while a great font, does not contain any CJK (Chinese, Japanese, Korean) glyphs. In most cases, it’s the job of the underlying UI framework to find a font that does support these glyphs. Revery should be no different, and the following is how I solved this problem in it.
The solution
Luckily we (the Revery team) were far from the first people to encounter this problem. Revery’s text rendering pipeline looks like this (extremely simplified):

This is the most simplified case: we already have a typeface loaded into memory and it supports all the glyphs we requested from it. In this case, we ask Harfbuzz, a text shaping library, to “shape” the text. In the case where the string is “ABC”, this is fairly trivial. However, since a single UTF-8 encoded character can take up multiple bytes, the shaping utility that Harfbuzz provides cannot be overstated. This is especially true in a language like OCaml/ReasonML, where for historical reasons (as described above), it’s assumed that all characters in a string take up a single byte.
A sample output from Harfbuzz can be seen below. For demonstration purposes, I chose to shape the string “κόσμε” because each character has a different size
-- κόσμε --
- SHAPE: GlyphID: 539 Cluster: 0
- SHAPE: GlyphID: 2690 Cluster: 2
- SHAPE: GlyphID: 305 Cluster: 5
- SHAPE: GlyphID: 541 Cluster: 7
- SHAPE: GlyphID: 304 Cluster: 9Here the glyph ID is the corresponding glyph in the string, and the cluster is the byte index of the character in the original string. It may not seem like it, but these two components are extremely helpful in implementing a fallback solution.
First, luckily the standard “unknown” glyph ID for all fonts is 0. If Harfbuzz comes across a cluster where the font has no corresponding glyph in the table, it will return the glyph ID 0. Let’s shape the string “ABC😃XYZ”:
-- ABC😀XYZ --
- SHAPE: GlyphID: 36 Cluster: 0
- SHAPE: GlyphID: 37 Cluster: 1
- SHAPE: GlyphID: 38 Cluster: 2
- SHAPE: GlyphID: 0 Cluster: 3
- SHAPE: GlyphID: 59 Cluster: 7
- SHAPE: GlyphID: 60 Cluster: 8
- SHAPE: GlyphID: 61 Cluster: 9As you can see, where the emoji occurs, the glyph ID is 0 (the font here is Arial). For our purposes, we’ll call any group of 0-glyphs a hole.
The next important piece of the puzzle is finding a font that can
render that glyph. Luckily, Skia provides an API for just that:
SkFontMgr::matchFamilyStyleCharacter. By simply giving it a
font family name (one to most closely match), a character, and a locale,
we can get a font back that is guaranteed to be able to render that
character. Awesome, right? Now we can create a basic fallback
implementation in pseudocode:
let glyphsAndClusters = Harfbuzz.shape(string);
let result = [];
for each glyph and cluster pair:
if glyph == 0:
let typeface = Skia.matchCharacter(...);
let character = String.utf8CharacterAt(cluster);
let newGlyph = Harfbuzz.shape(character);
add(result, newGlyph); Hooray! It works*!
“What’s the asterisk for?” you may be wondering. Well, if only it were that simple! Many UTF-8 characters you would think of as a single character are actually multiple. For instance, all emoji flags are actually the region codes of the country they represent: 🇺🇸 is 🇺 🇸, 🇮🇱 is 🇮 🇱, 🇯🇵 is 🇯 🇵 , etc. Fun fact: an old bug in Twitter actually counted flags as two of your 140 characters! Surely font shaping algorithms have improved since then! Anyway, what happens when we try to render one of these flags in Revery?
Dang! To be expected, but annoying nonetheless. Alright, how about we try refactoring our API to shape holes together? Unfortunately this algorithm is a bit too long to condense into easily understandable pseudocode, but if you’re curious, you can check out the actual implementation here. Basically, we create a recursive function to group all the contiguous holes together, shape the substrings that represent the holes, and reassemble the string into an array of shapes. Since OCaml lacks first class UTF-8 support, we had to leverage a library called Zed to find the UTF-8 bounds in a string. This complicates things a little bit, but luckily Zed’s API is pretty easy to understand. Let’s test that flag again:

Success! Although this may be simplistic compared to the fallback algorithms in Blink or Gecko, it’s not as far off as you might think! In fact, much of the inspiration I got from this algorithm came from this incredibly helpful document. There is a lot of corporate boilerplate that complicates the actual underlying algorithm in the Blink source, but the core idea is still the same.
Not only do we get emoji flags, we also get those Japanese characters we couldn’t see earlier:
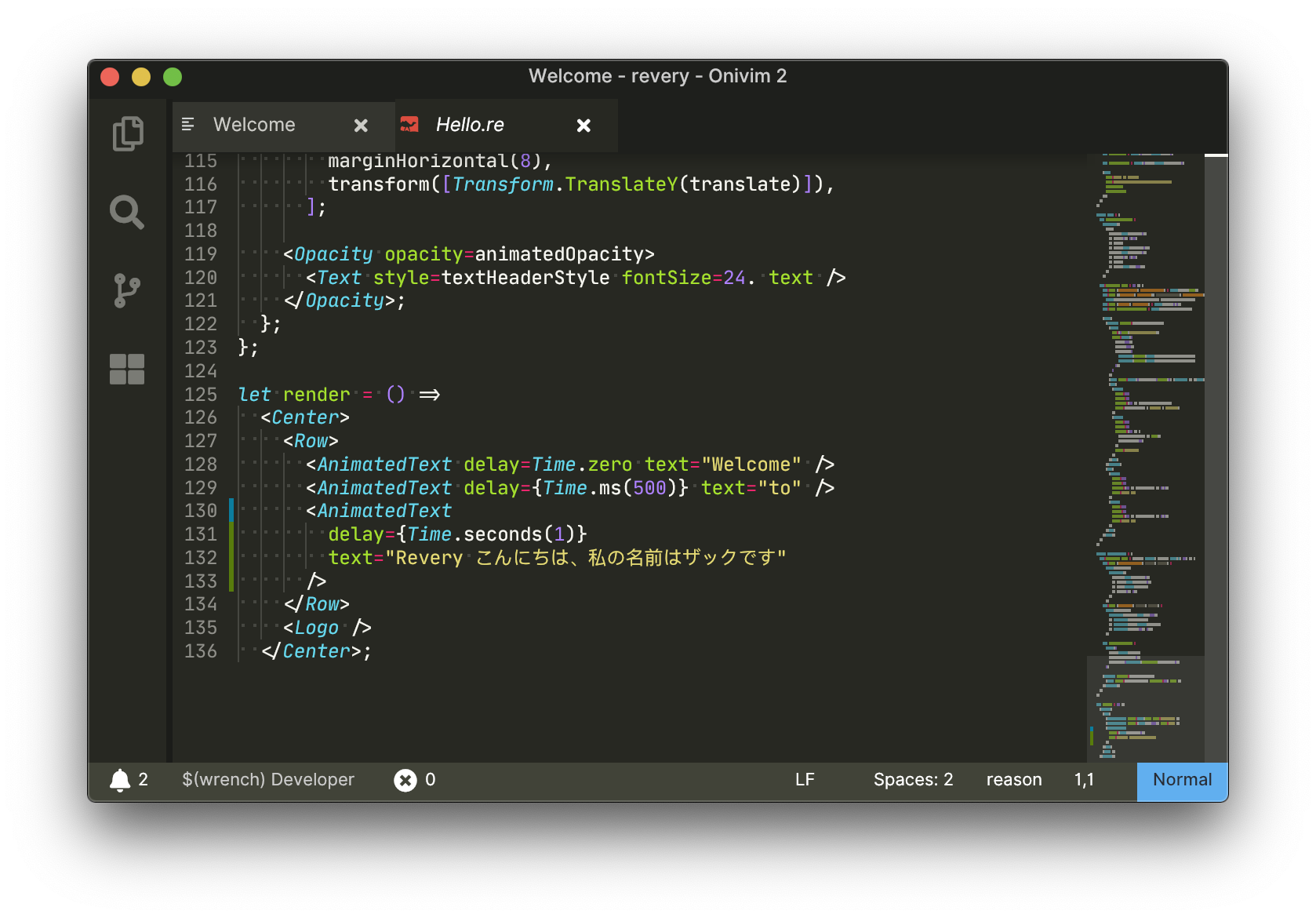
Beautiful, if I may say so myself 😎.
Special thanks
Although this may not seem that complex, this was one of the largest PRs I’ve ever written for Revery. There were a lot of holes (pun intended) that were exposed when we were expecting UTF-8 strings to “just work”. One of the biggest was text wrapping. One of my good friends (the one who introduced me to Revery in the first place), Ohad Rau, wrote the text wrapping algorithm initially, and he was extremely helpful in my quest to get the algorithm UTF-8 compliant.
I also want to thank Bryan Phelps and Glenn Slotte for some algorithm suggestions and improvements. Both of them have been immensely helpful not only for this feature, but the entire summer. I’ve learned so much during this summer, and I’m incredibly grateful to Bryan for giving me this opportunity.
